Crawling vs Web Scraping: Key Differences and Use Cases
 2025.08.12 03:11
2025.08.12 03:11 petro
petroIn today’s data-driven world, businesses, researchers, and developers rely heavily on automated tools to access information from the web. Two terms often appear in this context — web crawling and web scraping.
While they are related, they serve different purposes. Understanding the difference between crawling and scraping can help you choose the right method for your project, avoid legal pitfalls, and optimize your workflow.
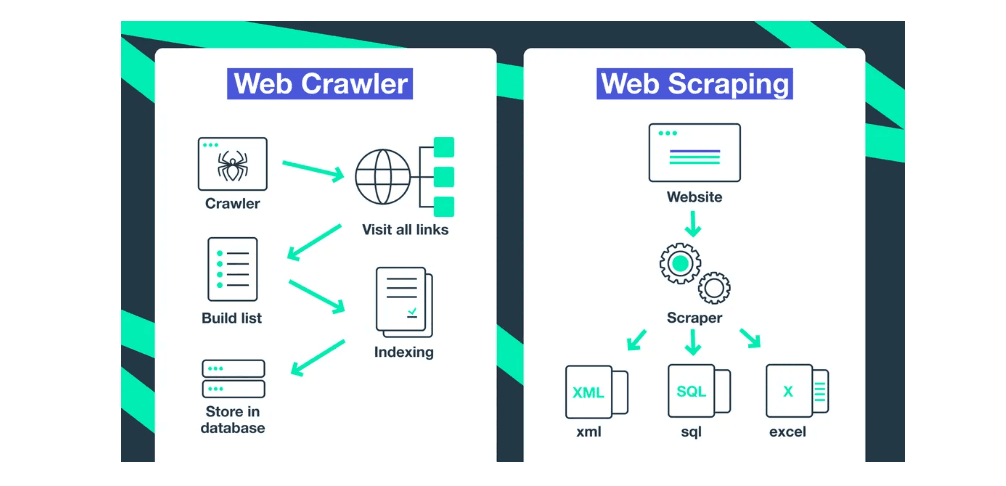
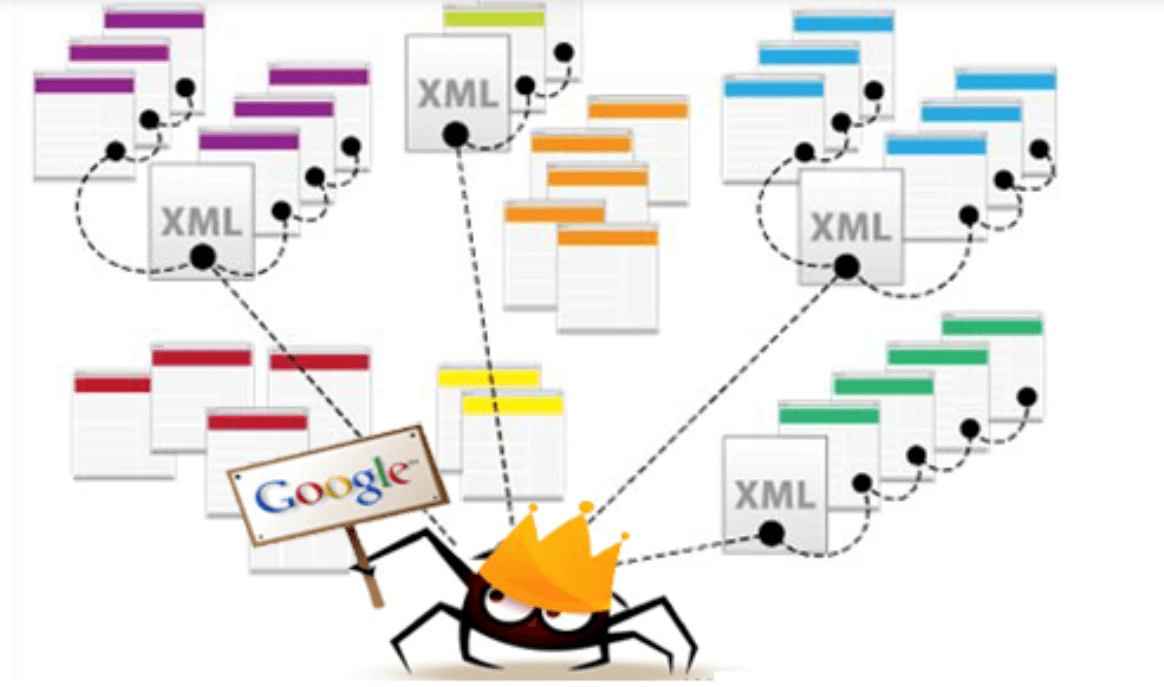
What Is Web Crawling?
Definition:
Web crawling is the process of automatically navigating the web to discover and index web pages. A program known as a crawler or spider starts with a list of initial URLs (seed URLs) and follows links on each page to discover new ones.
How It Works:
The crawler visits a starting URL.
It reads the page and collects all links.
It adds new URLs to its list.
The process repeats until all reachable pages are found or limits are reached.
Key Features:
Focuses on finding and mapping web pages.
Does not necessarily extract data from the pages.
Used for creating large indexes or keeping track of website changes.
Examples:
Googlebot indexing the web for Google Search.
Tools like Screaming Frog crawling websites for SEO analysis.
What Is Web Scraping?
Definition:
Web scraping is the process of extracting specific data from web pages and converting it into structured formats like CSV, JSON, or a database.
How It Works:
The scraper loads the target web page.
It parses the HTML structure.
It extracts the relevant elements (e.g., product names, prices, reviews).
The data is stored for analysis or integration.
Key Features:
Focuses on content extraction rather than finding URLs.
Often uses selectors (CSS, XPath) to pinpoint data.
Can use headless browsers like Puppeteer for dynamic pages.
Examples:
Extracting stock prices from financial websites.
Gathering restaurant reviews from TripAdvisor.
Crawling vs Scraping: The Main Differences
| Feature | Web Crawling | Web Scraping |
|---|---|---|
| Purpose | Discover and index web pages | Extract specific data from web pages |
| Output | List of URLs or site map | Structured data (CSV, JSON, database) |
| Tools Used | Scrapy (crawl mode), Apache Nutch, Heritrix | BeautifulSoup, Puppeteer, Selenium |
| Data Focus | Page location | Page content |
| Example | Googlebot finding all pages on a blog | Script extracting blog titles and authors |
When to Use Crawling
Building a search engine index.
Collecting URLs for later scraping.
Monitoring website changes and updates.
Detecting broken links or duplicate content.
When to Use Scraping
Price comparison websites.
Lead generation from public directories.
Market research through review analysis.
Academic research and statistical data collection.
Legal and Ethical Considerations
Always check the website’s Terms of Service.
Respect robots.txt rules for crawling.
Avoid overwhelming servers with excessive requests.
Use scraping responsibly, especially for copyrighted or sensitive data.
How Crawling and Scraping Work Together
In many real-world projects, crawling comes first to gather a list of relevant URLs, followed by scraping to collect specific information from those pages.
Example: An e-commerce price comparison tool may crawl multiple online stores to find product pages, then scrape product details like name, price, and availability.
Conclusion
Crawling and scraping are essential techniques in the world of web automation, but they serve distinct roles:
Crawling is about finding and mapping web pages.
Scraping is about extracting and structuring data.
For best results, understand your data needs, choose the right tools, and follow ethical practices.
 Multi-Account Management
Multi-Account Management Prevent Account Association
Prevent Account Association Multi-Employee Management
Multi-Employee ManagementRecommended
See More ![]()