How to Scrape Data from Twitter X And Is It Even Legal 2026 Guide
 2026.04.29 08:41
2026.04.29 08:41 BitBrowser
BitBrowserScraping data from Twitter X is a common strategy used for market research trend analysis lead generation and AI training
The key question remains whether it is actually legal
The answer is not a simple yes or no
This guide explains what scraping means when it is legal when it becomes risky how to do it safely and what to avoid
What Is Twitter X Data Scraping
Data scraping refers to collecting information automatically using scripts tools or software
On X this can include tweets user profiles hashtags and engagement metrics such as likes reposts and replies
Instead of manual copying scraping tools allow users to extract large amounts of data quickly and efficiently
Is Scraping Twitter Legal
Short Answer
It depends
When Scraping Is Generally Legal
Scraping is usually allowed under certain conditions
The data must be publicly accessible without requiring login access
You should not bypass technical protections
You must comply with applicable laws and platform rules
In some jurisdictions courts have ruled that scraping public data can be legal when it does not involve hacking or restricted access
When Scraping Becomes Risky Or Illegal
Scraping may become risky or illegal in the following situations
Accessing data behind login walls
Using fake or automated accounts to collect data
Bypassing protections such as CAPTCHA or rate limits
Collecting personal or sensitive data without a valid legal basis
These actions may violate privacy laws such as GDPR or computer misuse regulations
Terms Of Service Considerations
Even if scraping is technically legal it may still violate the platform terms of service
This can lead to account suspension IP blocking or legal action in some cases
Platforms including X have previously taken action against unauthorized scraping
The Three Key Factors That Determine Legality
What You Scrape
Public data presents lower risk
Private or personal data carries higher risk
How You Scrape
Respectful limited requests are safer
Aggressive automation increases risk
What You Do With The Data
Using data for internal analysis is safer
Republishing or selling data increases legal exposure
Why Scraping Twitter Has Become More Difficult In 2026
X has significantly restricted access to its platform
There are now paid APIs stricter rate limits and stronger anti bot detection systems
Scraping now requires not only technical skills but also compliance awareness and infrastructure planning
Common Methods To Scrape Twitter Data
Official API
This is the safest method
It is fully compliant and provides reliable structured data
However it can be expensive for large scale usage
Web Scraping Tools
These tools allow extraction of public data directly
They offer flexibility but come with higher legal and technical risks
Hybrid Approach
This method combines API access with scraping techniques
It helps balance data availability with compliance considerations
Detection Is The Real Challenge
Even if scraping is legal it can still result in access restrictions
Platforms monitor browser fingerprints IP patterns and automation behavior
This can lead to IP bans account restrictions and limited access to data
The Role Of BitBrowser In Scraping Workflows
BitBrowser does not make scraping legal but it plays an important role in maintaining a stable and consistent environment
It helps teams manage multiple browser sessions in a controlled way while reducing abnormal behavior signals that often trigger detection systems
With BitBrowser users can create isolated browser profiles that each have their own fingerprint cookies and session data
This allows more natural browsing behavior compared to running multiple automated scripts from a single environment
BitBrowser also helps maintain consistency in IP and device signals which reduces the likelihood of triggering platform security systems
For teams involved in research growth marketing or data collection workflows this type of infrastructure is important for long term stability
However it is still essential to follow legal guidelines and platform rules when using any tool including BitBrowser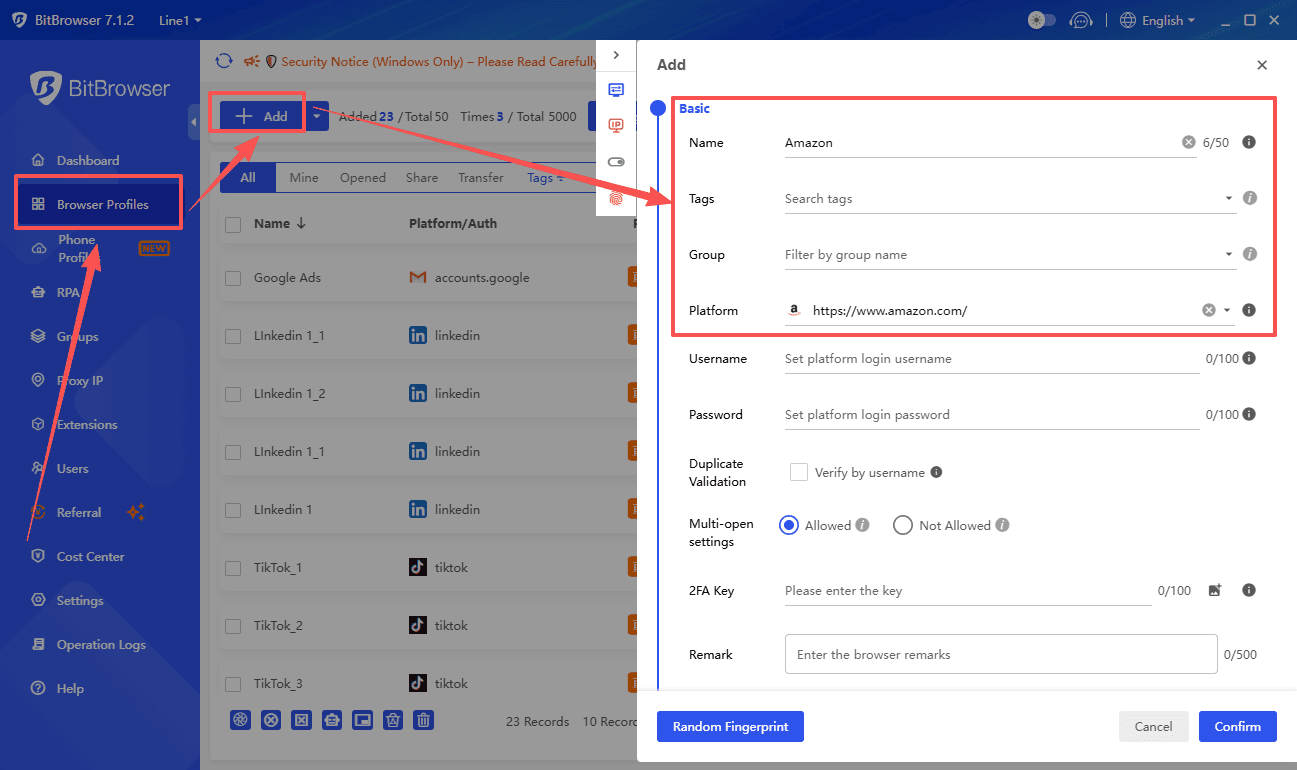
Best Practices For Safe Scraping
Focus only on publicly accessible data
Respect platform limits and avoid excessive requests
Be cautious when handling user data and follow privacy laws
Do not bypass technical protections
Maintain stable environments and consistent sessions
What To Avoid
Do not scrape private profiles
Do not use fake accounts for data extraction
Do not republish copyrighted content without permission
Do not ignore platform rules
Do not run aggressive automated systems at large scale
Key Takeaways
Scraping Twitter is not automatically illegal
Risk depends on the method of access the type of data and how the data is used
Public data scraping is generally acceptable under proper conditions
Scraping private or protected data carries significant legal risk
The main challenge is maintaining compliance while avoiding detection
Conclusion
Scraping Twitter X data in 2026 exists in a legal gray area
To reduce risk focus on public data respect legal and ethical boundaries and avoid aggressive automation practices
BitBrowser can support this process by providing a stable environment for managing sessions and reducing detection signals
For more advanced workflows combine a strong data strategy with reliable infrastructure
This approach allows teams to extract value from data while minimizing the risk of restrictions or penalties
 Multi-Account Management
Multi-Account Management Prevent Account Association
Prevent Account Association Multi-Employee Management
Multi-Employee ManagementRecommended
See More ![]()