How to Scrape X.com (Twitter) in 2026
 2025.12.25 08:18
2025.12.25 08:18 petro
petroScraping X.com (formerly Twitter) in 2025 is significantly more challenging than it was just a few years ago. Since the shutdown of the free API in 2023, X.com has introduced frequent and aggressive anti-scraping measures that break custom scrapers every few weeks. This guide explains why scraping X.com is difficult, what keeps breaking, and the most practical way to collect data reliably in 2026.
Why Scraping X.com Is So Difficult in 2026
X.com actively fights automated data collection. The platform updates its defenses every 2–4 weeks, forcing developers to constantly adapt.
The biggest challenges include:
Expiring guest tokens
Rotating GraphQL
doc_idsStrict rate limits
Advanced IP and fingerprint detection
Maintaining a DIY scraper now requires ongoing reverse engineering and monitoring.
The End of the Free Twitter API
In early 2023, X.com discontinued its free API access. The official paid API now starts at $42,000 per year, offering very limited access.
For most developers, startups, and researchers, this pricing makes the official API impractical—pushing scraping to be the only viable option.
What Breaks Most X.com Scrapers
1. Guest Tokens
Guest tokens are required for all GraphQL requests:
Expire every few hours
Are tied to IP addresses
Change acquisition methods frequently
Once a token expires, all requests fail until a new one is generated.

2. doc_id Rotation
Each GraphQL query uses a doc_id:
Rotates every few weeks
Has no public documentation
Must be reverse-engineered from frontend JavaScript
Outdated doc_ids cause silent failures or empty responses.
3. Rate Limits & IP Blocking
X.com enforces:
~300 requests per hour per IP
Instant blocking of datacenter IPs
TLS and browser fingerprint detection
Without residential proxies and realistic browser behavior, scraping fails quickly.
The Real Maintenance Cost of DIY Scraping
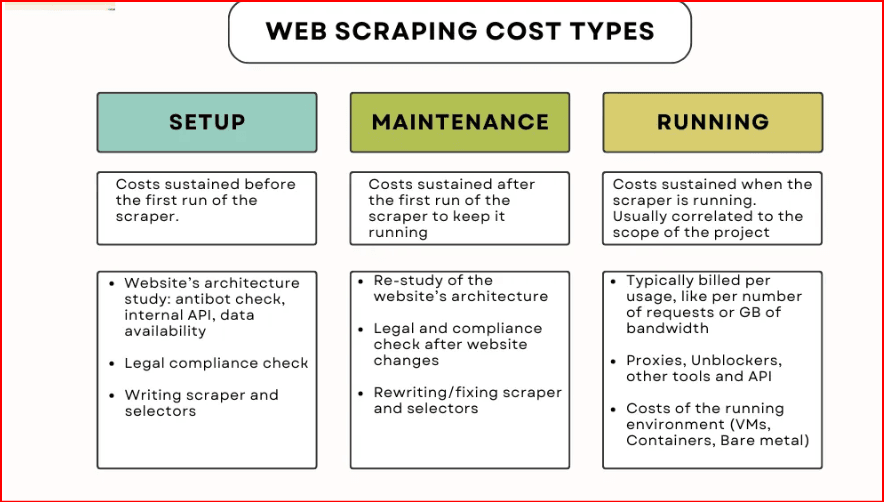
Running your own scraper requires:
Constant monitoring of API failures
Reversing new
doc_idsUpdating token logic
Managing proxy pools
Implementing rate-limit backoff strategies
On average, this costs 10–15 hours per month just to keep a scraper working.
What Data Can Be Scraped Without Login
Without authentication, you can still scrape:
Public profiles
Public tweets
Engagement counts (likes, replies, reposts)
Threads and replies
Public search results (limited)
You cannot access private accounts, bookmarks, or full timelines without login.
The Most Practical Solution in 2026
Instead of maintaining your own scraper, the most reliable approach is using a maintained scraping solution that updates automatically when X.com changes.
A maintained scraper:
Automatically handles guest tokens
Tracks and updates
doc_idsIncludes residential proxy rotation
Mimics real browser behavior
Updates within hours—not weeks
This removes the ongoing maintenance burden entirely.
How X.com Data Is Loaded (Simplified)
X.com works as follows:
Page loads minimal HTML
JavaScript requests a guest token
Token is validated and bound to IP
GraphQL queries are sent using
doc_idsJSON responses are returned and rendered
A working scraper must replicate this flow exactly.
Best Proxy Strategy for X.com Scraping
Residential proxies are mandatory.for this you use BitBrowser

Best practices:
Use sticky sessions (10–15 minutes)
Rotate IPs slowly
Avoid datacenter proxies entirely
Match IP location with browser fingerprint
Datacenter IPs are blocked almost instantly.
Legal Considerations
Scraping public data is generally legal in many jurisdictions.
However, X.com’s Terms of Service restrict automated access.
Always:
Scrape responsibly
Avoid excessive request rates
Consult legal counsel for commercial use
Final Thoughts
Scraping X.com in 2025 is no longer about writing clever code—it’s about maintaining it continuously. With frequent platform changes, DIY scrapers break often and demand significant ongoing effort.
For anyone needing reliable, scalable X.com data, a maintained scraping solution is now the most practical and cost-effective approach.
 Multi-Account Management
Multi-Account Management Prevent Account Association
Prevent Account Association Multi-Employee Management
Multi-Employee ManagementRecommended
See More ![]()